알고리즘의 성능을 측정하는 방법
1. 절대 시간 측정하기 - 직접 초시계를 들고 경과 시간을 측정하기
PC의 성능에 따라 수행 시간이 달라지므로 알고리즘 성능을 측정하기에는 적합하지 않음.

2. 연산 횟수 측정하기 - 코드의 연산 횟수를 측정하기
코드가 동일하다면 연산 횟수도 항상 일정하므로 적합함.
-> 성능을 측정한다고 했을 때는 연산 횟수를 측정하는것.
연산
연산의 종류
1. 반복문의 수행 횟수
1부터 N까지 합 구하기(단일 반복문)
-> 반복문이 N번 수행됨.
2차원 행렬(N*M 크기의 행렬)의 덧셈(중첩 반복문)
-> 반복문이 N * M번 수행됨.

2. 비교 / 대입/ 산술 연산자 사용 횟수
값의 비교, 대입 또는 컨테이너(배열 벡터)의 비교, 대입
단순 비교 대입은 연산에 큰 영향을 안끼칠것 같지만 데이터 크기가 큰 경우 충분히 고려할 만한 중요한 연산이 된다.
예를 들어 크기가 1000만 개인 배열을 비교하거나 각 원소들끼리 합을 구하려면 연산을 1000만번 수행해야한다.

그림처럼 변수의 크기나 배열의 원소 수에 따라 비교에 필요한 비용이 달라질 수 있다.
조건에 따라서도 연산 횟수는 달라진다.
1차원 배열에 있는 특정 원소를 찾는 작업을 로직에서 찾는 원소가 없을 경우도 있고, 바로 찾는 경우도 있다.
이러한 경우에 연산 횟수는 찾는 값에 따라 달라진다.


빅오 표기법(점근적 상한)
코딩 테스트는 내 코드가 제한 시간 안에 정답을 반환해야 하므로 최악의 경우에도 제한 시간 안에 문제를 해결하는 것이 중요하다.
최악의 경우를 기준으로 점근적 표기법을 활용해서 성능을 표현하는 방법을 빅오 표기법 이라고 하며 점근적 상한 이라고도 한다.
점근적 표기법의 개념
코딩 테스트에서 확인하려는 것은 정확한 연산 횟수가 아니다. 내 코드가 제한 시간 내에 문제를 해결할 수 있는지 여부다.
따라서 연산 횟수의 추이를 파악하면 충분하다. 즉 연산 횟수에 가장 많은 영향을 주는 부분을 기준으로 그 변화 양상을 분석하는게 핵심이다. 이렇게 연산 횟수의 추이를 기준으로 성능을 표현하는 방법을 점근적 표기법 이라고 한다.
입력값 x 따른 연산 횟수의 추이를 나타낸 함수를 f(x)라고 하고 또 다른 함수 g(x)가 어떤 특정 지점부터 항상 C*g(x) ≥ f(x) 조건을 만족 한다면 g(x)는 f(x)의 점근적 상한 이라고 할 수 있다.
아래의 그래프에서 보라색 원을 기준으로 이후부터 항상 g(x)가 f(x)보다 크므로 g(x)는 f(x)의 점근적 상한이라고 볼 수 있다.

아래의 그래프는 특정 지점부터 항상 g(x)가 f(x)보다 큰 지점이 없기 때문에 g(x)가 f(x)의 점근적 상한이라고 할 수 없다.

입력값이 작은 경우 성능 차이가 크게 드러나지 않기 때문에 알고리즘의 성능은 일반적으로 입력값이 충분히 큰 경우를 기준으로 평가한다. 즉, 입력값이 충분히 큰 경우 = 그래프에서 특정 지점(보라색 원)을 기준으로 이후를 뜻한다.
입력값이 커지면 상대적으로 상수값은 영향력이 적으므로 무시할 수 있다.
전체적인 추이는 x 값에 따라 결정되며 g(x)가 상한이라면 앞에 어떤 C가 와도 크게 문제가 없다.
-> C가 뭐가 오든 g(x)가 항상 f(x)보다 크므로 영향력이 적다는 뜻.
어떤 연산 횟수 f(x)에 대한 점근적 상한 g(x)는 하나가 아니라 여러 개일 수 있다.
점근적 상한이 여러 개 존재한다면 가능한 실제 연산 횟수와 가까운 최소한의 상한을 구해야 한다.(가장 타이트한 상한)
최소한의 상한 구하기
가장 많은 영향을 미치는 부분만 남기고 앞에 있는 상수를 없애면 된다.
다항식의 경우에는 최고차항만 남기고 계수를 제거하면 된다.
최고차항만 남기고 다 제거하는 이유는 x값이 커지면 다른 차항은 무시할 정도로 차이가 벌어지기 때문에 의미가 없다.

위 식을 빅오표기법으로 표기하면 최고차항인 n차항만 남기고 계수인 a를 제거한 O(xn)이다.
다항식과 지수함수, 로그함수가 섞여있는 경우에 아래 그래프를 보고 무엇을 남겨야 할지 명확하게 알 수 있다.
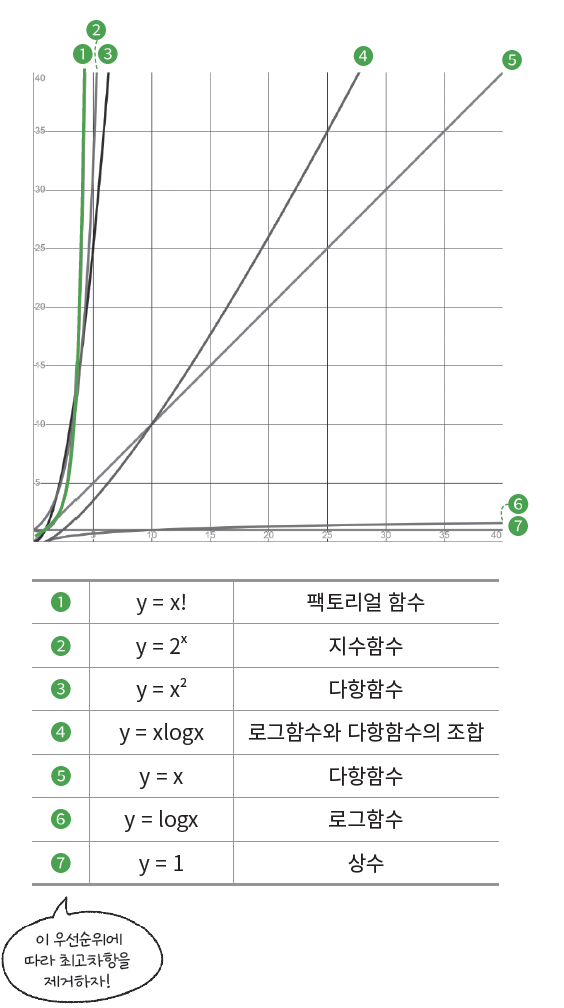
가장 기울기가 큰 (= 가장 값이 빠르게 증가하는) 함수만 표기하면 되는것같다.

1차원 배열을 탐색하는 경우의 시간 복잡도는 O(N)이다.
2차원 배열을 순회하는 경우 O(N2)이다.
탐색 범위를 반복해서 절반으로 줄여 나가는 경우 시간 복잡도는 O(log N)이다.
O(log N)인 이유
N(1/2)k= 1
(1/2)k = 1/N
2k = N
k = log N
N 개의 원소로 만들 수 있는 모든 조합의 시간 복잡도는 O(2N)이다.
점근적 상한 기준 최대 연산 횟수

최대 입력값이 100만 개라면 O(NlogN) 보다 복잡한 알고리즘을 사용하면 무조건 시간 초과가 발생한다고 생각하면 된다.
'코딩테스트 공부' 카테고리의 다른 글
| 효율적인 코드 구현하기(벡터vs덱, 정렬이 필요없는데 정렬하는 경우, 특정 원소 찾기, 문자열 결합하기, auto& vs auto) (0) | 2025.09.29 |
|---|---|
| STL 사용하기(반복자, 컨테이너(vector, set, map), 알고리즘(sort, find, count, unique)) (0) | 2025.09.29 |
| 입력값 처리(숫자 반올림, 올림, 내림, 문자열 스트림, 진법 변환) (0) | 2025.09.29 |
| 자주 하는 실수(단락 평가, off by one, 0으로 나누기, 중간 값의 오버플로) (0) | 2025.09.26 |
| 문자열 메서드(find, append, replace, substr 등) (0) | 2025.09.26 |