벡터vs덱
벡터는 배열과 동일하게 메모리가 연속적으로 할당된다. 따라서 임의 접근이 가능하다.

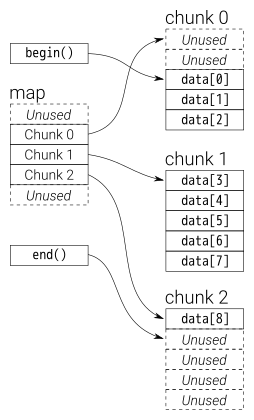
덱은 맨 앞의 원소와 맨 뒤의 원소를 가리키는 포인터가 있고 내부적으로 데이터는 여러 개의 청크라고 불리는 영역으로 쪼개져 있다. 이는 임의 접근을 효율적으로 하기 위한 전략이다.
맨 앞의 원소를 추가, 삭제하는 경우
벡터의 경우에는 맨 앞 원소를 추가, 삭제하는 경우 뒤에 있는 원소들이 전부 이동을 해야한다.
만약 데이터가 N개라면 N-1개 원소들이 한 칸씩 이동해야 하기 때문에 O(N) 연산이 된다.
반면에 덱의 경우에는 청크를 나눠서 관리하기 때문에 O(1) 연산이 된다.
따라서 맨 앞의 원소를 추가하거나 삭제하는 경우 덱을 사용하는게 좋다.

임의 접근을 하는 경우
벡터와 덱 모두 O(1) 연산이다.
덱의 경우 각 청크가 불연속적이지만 이들을 관리하는 map을 내부적으로 관리하기 때문에 O(1)이다.
하지만 데이터가 커지면 map을 통해 청크 위치를 찾고 접근하는데 필요한 연산 횟수가 증가해서 성능 차이가 꽤 난다.
따라서 임의 접근을 빈번하게 하는 경우에 벡터를 사용하는게 좋다.

정렬이 필요없는데 정렬하는 경우
원소가 삽입될 때마다 자동으로 정렬하는 컨테이너가 있다. (map, set 등)
편리하지만 매번 원소가 삽입 될 때마다 정렬을 수행하므로 효율성이 떨어질 수 있다.
STL에서 제공하는 컨테이너 중 내부 정렬을 하는 컨테이너는 데이터를 레드-블랙 트리로 관리한다.
간단하게 균형 잡힌 이진 탐색 트리라고 생각하면된다.
원소 삽입 / 삭제 / 탐색 모두 O(log N)이다.

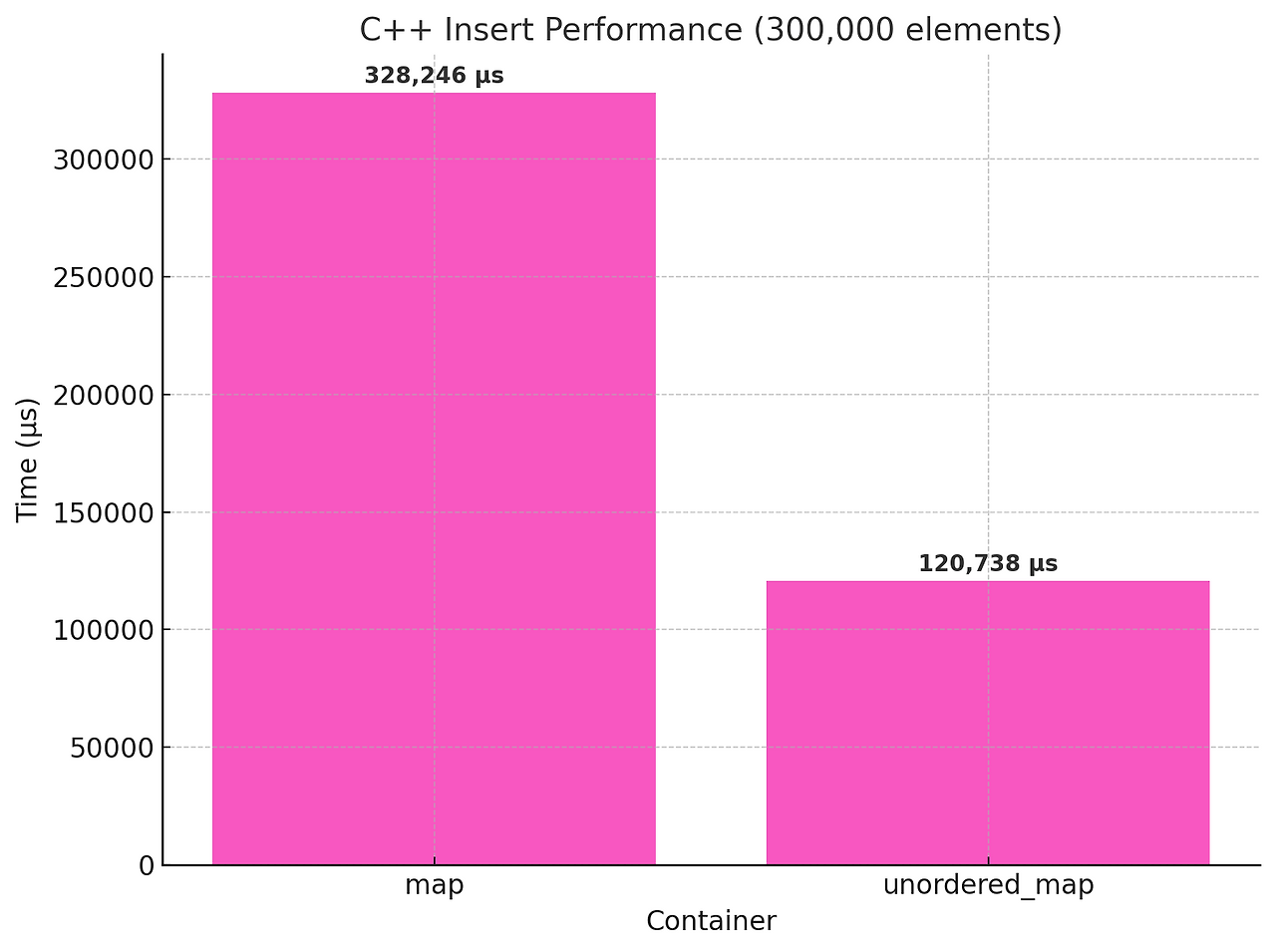
맵(map, 트리) vs 비정렬 맵(unordered_map, 해시)
가장 흔한 케이스가 키 순으로 정렬할 필요가 없는데 맵을 사용하는 경우이다.
맵의 경우 원소가 N개인 상황에서 키가 삽입될 경우 정렬을 수행하기 때문에 O(log N) 연산이 발생한다.
삽입될때마다 발생하는 연산이므로 누적되면 성능 차이가 꽤 난다.(해시의 경우 삽입, 삭제, 탐색 모두 O(1))
따라서 키값을 기준으로 정렬을 할 필요가 없다면 unordered_map을 사용해야 한다. set도 똑같다.
특정 원소 찾기
데이터가 컨테이너에 저장된 상황에서 특정 원소를 찾는 경우에도 성능 차이가 크게 발생한다.
vector
벡터는 선형 컨테이너고 특정 데이터에 접근하기 위해서는 해당 데이터의 인덱스를 통해 임의 접근해야한다.
인덱스 자체에는 데이터에 대한 특별한 정보가 없기 때문에 순차 탐색을 해야하므로 데이터가 N개 일 때 특정 원소를 찾는 연산은 O(N)이다.
set과 map
set과 맵은 데이터를 레드-블랙 트리로 관리하여 특정 원소를 찾는 연산은 O(log N)이다.
unordered_set과 unordered_map
unordered가 붙는 컨테이너는 해시 기반으로 관리하여 특정 원소를 찾는 연산은 O(1)이다.

문자열을 결합하는 경우
문자열에 문자를 추가하는 연산의 경우에도 큰 성능의 차이가 발생할 수 있다.
기존 문자열에 문자를 추가하는 방식이 있는 반면, 아예 문자를 추가할 때마다 새로운 문자열을 만드는 방식이 있다.
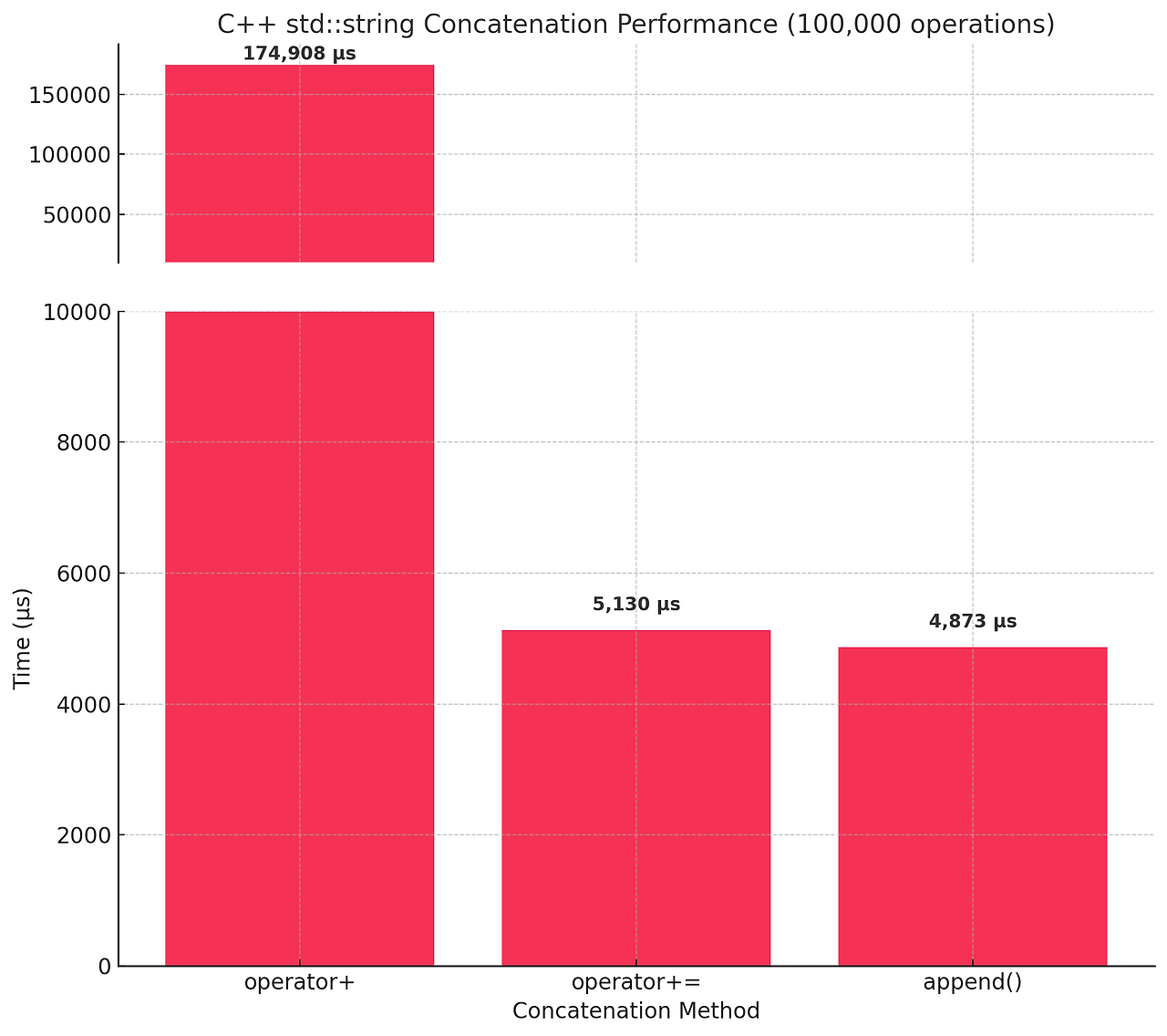
+ 연산자
+ 연산자로 문자열을 결합하는 경우, 매번 새로운 문자열을 다시 만든다.
새로운 문자열을 추가할 때마다 문자열을 새로 만들어서 기존 문자열 길이가 N이라면 O(N)이다. 쓰면안된다.
+= 연산자와 append() 메서드
+= 연산자와 append() 메서드는 매번 문자열을 새로 만들지 않고 기존 문자열에 덧붙이는 방식이다.
따라서 문자열 길이에 상관없이 연산은 O(1)에 가깝다.
auto& vs auto
반복문을 사용할 때 auto로 받는 것과 auto&로 받는 것은 생각보다 큰 성능 차이가 발생할 수 있다.
전자는 복사가 발생하지만 후자는 복사가 발생하지 않기 때문이다.

'코딩테스트 공부' 카테고리의 다른 글
| 재귀 함수 (0) | 2025.09.30 |
|---|---|
| STL 사용하기(반복자, 컨테이너(vector, set, map), 알고리즘(sort, find, count, unique)) (0) | 2025.09.29 |
| 입력값 처리(숫자 반올림, 올림, 내림, 문자열 스트림, 진법 변환) (0) | 2025.09.29 |
| 자주 하는 실수(단락 평가, off by one, 0으로 나누기, 중간 값의 오버플로) (0) | 2025.09.26 |
| 문자열 메서드(find, append, replace, substr 등) (0) | 2025.09.26 |